
构建发布-前端应用
配置 探针,有了健康检查,k8s 才能更有意义。
构建镜像
需要一个 Makefile 和 一个 Dockerfile 来构建镜像。
build:
npm run docs:build
buildctl \
--addr tcp://buildkitd.cicd.svc.cluster.local:1234 \
build \
--frontend dockerfile.v0 \
--local context=. \
--local dockerfile=. \
--output type=image,name=hb.apihub.net/feling.net/pages:1.0.0,push=true# 使用一个基础镜像
FROM hb.apihub.net/nginx:stable
COPY nginx.conf.template /etc/nginx/templates/default.conf.template
# 将当前目录下的所有文件复制到镜像的指定路径
COPY ./dist /usr/share/nginx/html
# 暴露容器的端口
EXPOSE 80
# 启动Nginx服务器
CMD ["nginx", "-g", "daemon off;"]配置探针
这里重点说明一下,部署的时候,探针 的作用。
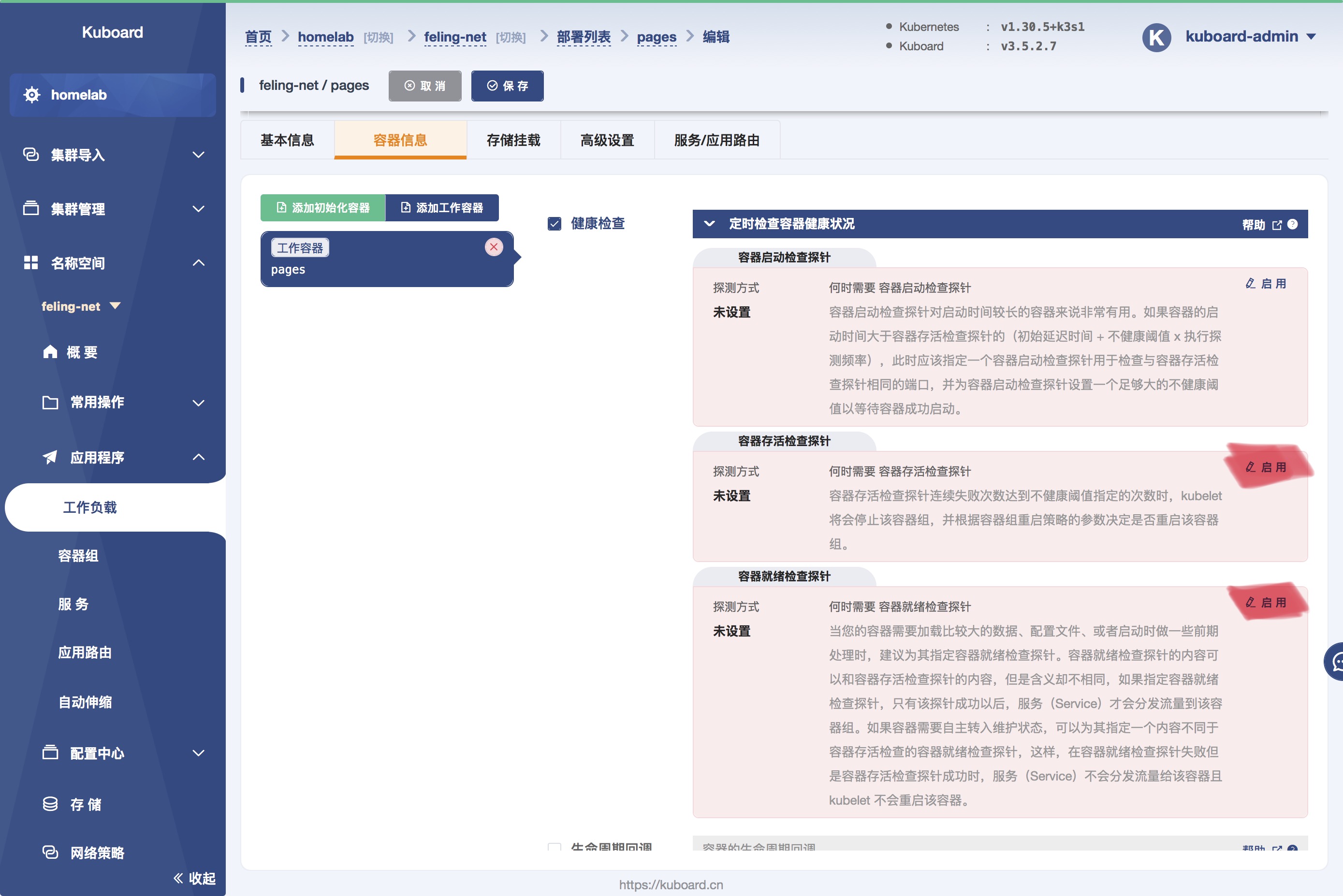
kuboard 界面上,已经有很好的说明了。这个一定要配,保底也要配一个 tcp 端口的检查。有健康检查,才能发挥出 k8s 调度的能力。
举个例子,
没有配探针的情况下,直接重启这个工作负载。同时在浏览器上不停的刷新这个工作负载对应的访问页面,会刷出来 500 的错误页面。
如果配置了探针,新旧版本的切换就很平滑,中间不会出现 500 的请求。
拓展阅读-中间件单节点部署
我的观点是:全用单节点,不要搞集群,除非性能不够
在探针的加持下,程序或者说容器发生故障,是可以自动被调度重启的。只要数据安全,单节点也是高可用的。而中间件使用的数据,我们已经做了可靠的持久化存储,把数据放在了外部带磁盘阵列的 nfs,或是集群内的分布式存储。
对比启动多个实例,使用中间件内置的高可用集群方案。在单个实例故障时,集群方案也是需要时间发现、切换的。这个时间消耗 与 k8s 的调度重启并没有太大的区别。或者主观上可以认为 k8s 的调度 会比 中间件自带的故障切换 慢那么几秒吧,真的差这几秒吗?你有那个本钱买到这几秒吗?这几秒原本是属于你的吗?这背后的运维成本你想装傻充楞让手底下牛马们自己背,回头再骂他们能力不行吗?面对中间件的故障,你的运维能力除了重启,有第二个处理手段吗?真的有人力学得会集群怎么搭吗?(>_< 糟糕,这几问应该写到杂记里写给自己看,不应该写到整理后的系列文章里。)
所以,在故障恢复能力这一点上,单节点与集群 是几乎打平的。在运维成本上,单节点是完胜的。集群唯一拿得出手的,就是它能提供比单节点更高的性能。如果需要那么高的性能,那肯定已经不差钱了,怎么做都对。